Going Where No GC Has Gone Before!
Garbage Collectors (GCs) are a critical component of a modern application stack. Long pauses, large memory consumptions, and high CPU usage can unexpectedly occur with certain workloads or series of events. These behaviors can make systems unresponsive, make it impossible to run them in resource-constrained environments, and are often very difficult to debug and fix – as their appearance may be intermittent and the issues are often intrinsic to GC systems themselves. In fact recent work has shown what, for most languages, these issues are unavoidable and, regardless of the GC design or implementation, there will always be workloads that cause them to occur!
Intriguingly, the pathological and scenarios that are needed to cause these issues depend on a specific set of language features – mutability and cyclic data structures. In previous posts we have discussed how these features impact mechanized analysis and how they are common sources of developer (human and AI!) errors. But, as it turns out, they are also the source of GC pathologies and, in fact, by designing a language (Bosque) that is easy to analyze we have also created a language that provides strong invariants that 1) the GC can rely on to optimize its behavior and 2) that, when combined with some careful implementation, allow us to prove that our new GC design for Bosque is free of all pathological behaviors!
Theoretical Guarantees
The first issue is to more precisely outline what behaviors we want to guarantee for the collector and memory management system more generally.
1) Bounded Collector Pauses: The collector only requires the application to pause for a (small) bounded period that is proportional to the size of the nursery. 2) Starvation Freedom: The collector can never be outrun by the application allocation rate and will always satisfy allocation requests (until true exhaustion). 3) Fixed Work Per Allocation: The work done by the allocator and GC for each allocation is constant – regardless of object lifetimes or application behavior. 4) Application Code Independence: The application code does not pay any cost, e.g. read/write barriers, remembered sets, etc., for the GC implementation. 5) Constant Memory Overhead: The reserve memory required by the allocator/collector is bounded by a (small) constant overhead
The first two properties are the most critical and are the ones that are often violated by pathological workloads. They are foundational to user perceived performance – long pauses to responses are annoying and application crashes due to out-of-memory conditions are obviously undesirable.
The next two properties are also important and are often violated in GC designs. The need to repeatedly visit objects (e.g. marked dirty and re-scanned after modification) is a parasitic cost that can lead to high CPU utilization and increased cache pressure (misses) that are difficult to predict and optimize for. Similarly, the cost for synchronizing the application and GC state (e.g. read/write barriers) is a smaller (5% direct) cost but, over the course of an application adds both the direct costs and indirect costs on every field write (read) operation.
The final property is often overlooked, as memory is often considered cheap on modern servers, but given the over-provisioning of memory required by many GC designs (e.g. 3-4x the live data), this can be a significant cost. This overhead can stack-up when running multiple applications on the same machine and is a challenge when moving to edge/embedded environments where memory is more constrained – and can require substantial work to port code to a more memory-efficient language (Rust/C++) or rework the application to target a specialized embedded target.
Key Language Features and Invariants
Looking at the structure of a garbage collector, and the pathological scenarios that cause it to violate one (or more) of the above properties, we can identify two common features. The first is if, at some point, the GC must have global knowledge of the heap connectivity graph in order to make progress. The second is if the mutator can take actions, outside of direct allocation, that increase the amount of work that the GC must do (e.g. by modifying objects that the GC has already visited).
In the cases of generational collectors like Java’s G1 (or reference counting collectors with cycles), the GC must have global knowledge of the heap connectivity graph to identify which objects are live. For these systems, it is clear that eventually, the collector will need to trace the entire heap and, as the heap size is arbitrarily large, the resulting tracing will induce an arbitrarily large pause – violating property 1 in addition to 4 and 5.
As an alternative we might consider an incremental collector like in Go or Java’s ZGC. These systems can avoid long pauses by breaking up the tracing work into smaller increments and interleaving it with application execution. However, these collectors are still vulnerable to workloads where the application allocates new objects and invalidates reachability information (faster) then the GC can trace and reclaim memory. The most common cases are when objects are modified repeatedly, which marks them as dirty, and thus must be re-scanned by the collector. In this case the collector will either need to fail on allocation (prematurely starve – violating property 2) or it will need to fall-back to a fully stop-the-world collector or degenerate collection (again violating property 1).
As noted in the introduction, these issues are not simply engineering challenges that may one day be solved but they are intrinsic to any GC design for languages with mutability and cyclic data structures. In contrast, the Bosque language has two key features that allow us to design a GC that is free of these pathologies:
- Immutability: The entity declaration in Bosqe creates a new composite datatype and these are always immutable. A key implication of this fact is that once an entity value is created then fields (and thus pointer targets) will never change.
- Cycle Freedom: In combination with the immutability of entities, and careful definition of constructor semantics, the Bosqe language ensures that all data structures are acyclic. This invariant allows us to utilize reference-counting techniques without concern for backup cycle-collection or other special case logic.
Pando GC Design
The absence of the above complications creates the potential for building a fully pathology free GC. However, this theoretical possibility does not give us a specific design. Thus, our challenge is to find a GC design (and implementation) that can leverage these language features and invariants to satisfy the above properties.
Looking at properties of GC designs, tracing vs reference counting (RC), a key item to note is that tracing is very good at quickly allocating and reclaiming memory while RC systems are excellent at short-pauses and only touching objects when lifetime events occur (e.g. deallocations). Thus, a natural design is to combine these two approaches – using tracing for the nursery and RC for the older generation. We are not the first to notice this, in fact this idea was proposed by two groups in 2003 [1, 2]. However, as they were working with Java, which has both mutation and cycles, their ability to leverage key features of this design were limited. In contrast, Bosque allows us to aggressively simplify the design and implementation of this combined tracing/RC collector!
In the Bosque collector design heap values can be in one of two logical regions, the nursery or the reference-counted old space.
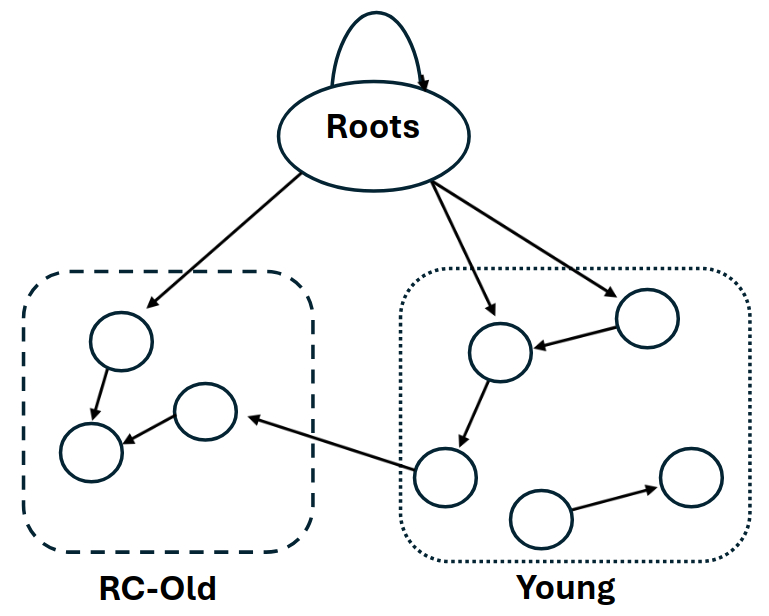
In this design the roots can point to values in the nursery, the RC-heap, or other stack allocated values. However, while there may be pointers from the nursery to the RC-heap, pointer are not allowed to go from the RC-heap into the nursery. This hierarchical relation ensures that objects in the nursery can be collected without concern for references from older objects which, by construction, cannot exist.
The first step in the collection algorithm is to trace and evacuate the young objects in the nursery. For each marked object we encounter in the tracing walk are two possibilities, the first is that the object is in the nursery and only referenced by other young objects, and the second is that the object is already in the RC-heap.
In the first case we can evacuate the object values to a compacting page, performing pointer forwarding as necessary, and converting the object to a reference counted representation (the objects in the dashed box). As each object is promoted to the RC-old space all fields are (precisely) scanned and reference counts for children are incremented (shown with black plus).
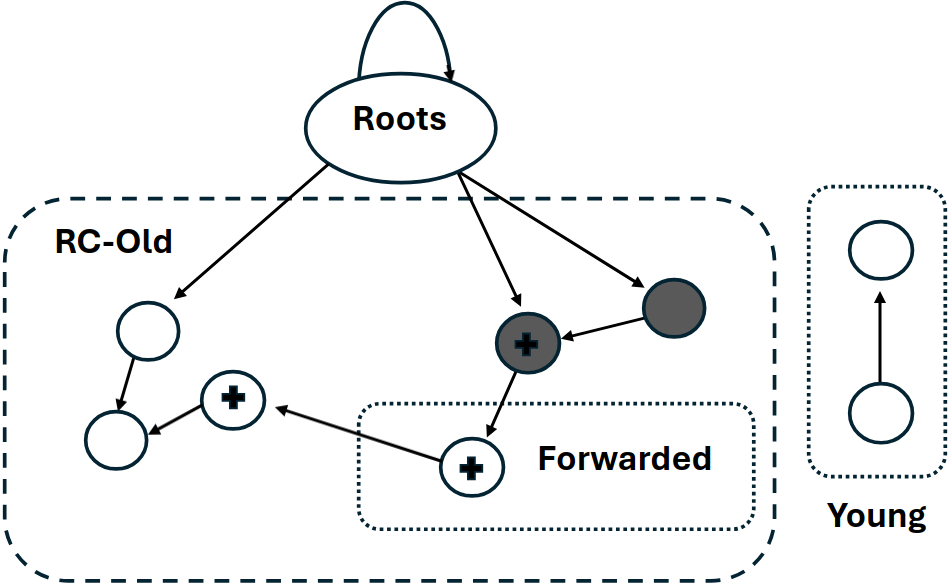
Next the algorithm sweeps the now mostly (or entirely) evacuated nursery and rebuilds the free-lists for the next round of allocation – allowing the collector to re-use both completely empty and semi filled pages. As RC objects are not moved the ability to re-use partially filled pages is critical to avoid fragmentation. The sweep reclaims the unmarked dead objects and the space cleared by the evacuation. In our example, there is only one object that remains on the page, the root referenced object, while all other slots are evacuated or reclaimed.
The final step in the collection algorithm is to process deferred reference count decrements and root reference status. Our implementation compares the root set from the previous collection with the root set identified in the current collection to determine which root references are no longer live. For each of these references the collector checks if the reference count has dropped to zero, in which case the object can be reclaimed. This reclamation is then a standard release walk of the object graph, decrementing reference counts and reclaiming objects as necessary.
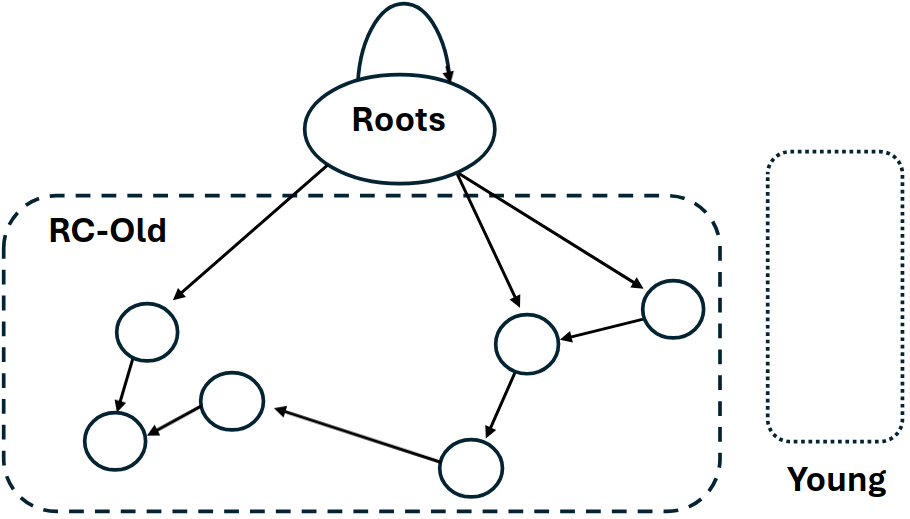
The most notable feature of this algorithm is not what it has but what doesn’t. Despite the use of a generational collector and reference-counting, there are no remembered sets, no write barriers, no backup cycle-collector, and no need for runtime support in the application code. As a result of these features, the cost of a collection cycle is independent of any application code behavior and can always be performed in a bounded time that is proportional to the size of the nursery – and the additional memory overhead is also a constant factor of the nursery size.
Experimental Results
For our experimental evaluation, we consider a set of benchmarks that exercise different aspects of the Bosque language and its garbage collector. The first is a Bosque implementations of the n-body simulations programs from the Computer Language Benchmarks Game. The next is a raytracing program published on Microsoft’s MSDN blog. The db program is a Bosque implementation of the DB benchmark from SpecJVM 98. The final benchmark is the optimizer pass of the Bosque compiler (written in Bosque).
The Pando collector is implemented in C++, 2.4kloc at present, and all experiments were run on a system with an AMD Ryzen 9 9950X and 64GB of memory. The system is otherwise unloaded. All runs use a default nursery size of 8mb and a default page size of 4kb.
| Benchmark | Code Size | Types | AllocCount | AllocMemory (GB) | Max Live Heap (KB) |
|---|---|---|---|---|---|
| n-body | 193 | 68 | 1,248,474,177 | 69.5 | 5.1 |
| raytracer | 273 | 34 | 822,135,153 | 34.4 | 2.8 |
| db | 304 | 71 | 1,970,703,992 | 92.3 | 46.9 |
| compiler | 5120 | 684 | 1,538,395,937 | 140.9 | 8,519 |
Static and dynamic statistics for the evaluation applications. Code Size is lines of Bosque source code and Types is the number of distinct Bosque types in the program. AllocCount is the total number of allocations, AllocMemory is the total bytes allocated, and Max Live Heap is the max live heap observed during execution.
GC Performance
The first evaluation is a throughput comparison between our new GC and an $\epsilon$-gc collector which allocates continuously from a bump buffer without any collections. We measure the total wall-clock time taken by the application and pause times for the collector.
| Benchmark | Pando (s) | ε-gc (s) | 50% Pause (μs) | 95% Pause (μs) | 99% Pause (μs) |
|---|---|---|---|---|---|
| n-body | 1.14 | 1.72 | 137 | 172 | 186 |
| raytracer | 1.03 | 1.18 | 151 | 198 | 214 |
| db | 1.16 | 1.66 | 170 | 216 | 231 |
| compiler | 1.13 | 1.64 | 166 | 213 | 258 |
Application wall-clock time comparison between our new GC and ε-gc collectors, and Pando pause time statistics at 50th, 95th, and 99th percentiles.
The results show that in all cases the new collector is actually faster than the $\epsilon$-gc collector by on average 25%. Our analysis indicates that this is due to the improved locality of the memory access patterns after copy-compaction out of the nursery which more than offsets the additional work required by the collector. The average pause times for the collector are quite low, with a 50% percentile pause time of 137μs-170μs across the benchmarks and a 99% percentile pause time of 258μs on any benchmark!
We also observe that the pause times are quite consistent across the benchmarks. Thus, as expected from the theoretical analysis, we see that the collector performance is largely invariant of the application workload and primarily a function on the nursery size.
Critically, the temporal behavior is not achieved at the expense of memory overheads The maximum heap size used by the application during the execution of the benchmark, measured as the size of all committed memory pages used in the computation, is under 17MB for every application – or only slightly more than the nursery size plus the live heap size.
| Benchmark | Collections | Survival Rate | GC %Time | Heap Size (MB) |
|---|---|---|---|---|
| n-body | 758 | 0.03% | 10.5% | 8.6 |
| raytracer | 245 | 0.007% | 3.7% | 8.6 |
| db | 553 | 0.31% | 12.4% | 8.7 |
| compiler | 615 | 0.36% | 9.5% | 16.1 |
The first two columns show the total number of collections performed by the Pando collector during the benchmark run and the average survival rate of the nursery (at 8MB). The next column shows the percentage of total application time spent in GC. The final column shows the max memory used by the application, runtime, and collector as measured by total page usage from the OS.
The GC %Time column is the percentage of total application time spent in garbage collection – this value is larger than is typical for a mature language/GC stack, however our analysis indicates that this is a function of an unoptimized GC codebase and high allocations rates incurred by the baseline implementations for persistent data-structures (lists and strings). Despite this, the values are still all under 12.5% for all benchmarks, indicating that the collector architecture is fundamentally performant.
These results demonstrate that the constant-factor overheads of the collector match the results in practice. Although our benchmark applications are limited in size the fundamental properties of the collector design, and theoretical guarantees, indicate that these results should hold for larger applications as well, Empirically, we note that the performance of the collector is largely invariant across the workloads and that, even in the face of heavy allocation, the collector does not experience long pauses or is ever out-run by the application.
Comparison with State-of-the-Art
The final experiment is a direct comparison between our new collector and modern state-of-the-art low-latency Java garbage collectors on the same benchmark. The binary-trees benchmark is a small, but widely used benchmark from the Benchmark Shootout, that is highly heap intensive. It is designed explicitly to stress GC algorithms by creating long-lived data structures while simultaneously allocating at a very high rate. For our purposes it is also possible to implement using exactly same code structure in both Bosque and Java allowing for a true 1-1 comparison of Bosque gc with an mainstream language and various heavily optimized state-of-the-art GC algorithms.
We compare our Pando GC with with ZGC and Shenandoah (in their default configurations), two modern low-latency garbage collectors for Java. These collectors are heavily optimized for concurrent and parallel collection, as opposed to Pando which is currently a baseline single-threaded implementation which fully pauses the application for the full collection cycle.
| Max Heap | ZGC Overhead | ZGC Time (secs) | Shenandoah Overhead | Shenandoah Time (secs) | Pando Overhead | Pando Time (secs) |
|---|---|---|---|---|---|---|
| Unlimited | 8.1 | 3.6/4.7 | 12.3 | 2.0/2.9 | 1.3 | 5.7/5.3 |
| 1.5× Live | 3.1 | 7.0/17.3 | 1.5 | 3.4/10.6 | 1.3 | 5.6/5.5 |
Direct comparison of Pando with state-of-the-art low-latency Java garbage collectors ZGC and Shenandoah on the binary-trees benchmark. The first column is the max heap size allowed, either unlimited or set to 1.5× the live heap size. The remaining columns show the memory over-provisioning overhead and time taken by each collector.
The first row in the table shows the results when the max heap size is unlimited allowing the collectors to use as much memory (up to 64 GB) and as many threads as desired (with a 16/32 core CPU). The Overhead columns show the memory over-provisioning factor as computed by the max heap size divided by the live heap size. The Time columns show the total time taken by the benchmark in terms of wall-clock time and CPU time over all threads (possibly running in parallel). As can be seen, both ZGC and Shenandoah are able to complete the benchmark in lower wall-clock time than Pando. However, this performance comes at the cost of significant memory overheads between 8.1× and 12.3× the live heap size – in the case of Shenandoah using 3.3GB when compared to 359MB for Pando.
The second row shows the result of the benchmark with the max heap size limited to 1.5× the live heap size (400MB). As shown in the table, both ZGC and Shenandoah experience severe performance degradation under this configuration with wall-clock time 1.7×-1.9× higher and CPU time spiking by nearly 3.6×. Conversely, Pando experiences no performance degradation under this configuration with both wall-clock and CPU times remaining stable.
Additionally, both ZGC and Shenandoah experience significant issues with GC pauses and application stalls under this configuration. The collectors report degenerate GC runs and forced synchronous collections as they are unable to keep up with the allocation rate. Conversely, Pando continues to operate normally with increased pauses due to the higher survival rates, and heavy RC workloads, but the fundamental characteristics of the collector prevent the emergence of pathological issues. In fact removing the RC decrement phase from the stop-the-world collection, e.g. by performing these operations concurrently on a background thread, is sufficient to keep the Pando 50% percentile times at 119μs and even the 99% percentile times under 10ms.
These results demonstrate that the Pando collector can provide comparable low-latency performance to state-of-the-art Java garbage collectors while being immune to fundamentally pathological behavior tradeoffs that are unavoidable in existing mainstream languages and runtimes.